
Python's Concurrency Tools: Multithreading, Multiprocessing, and AsyncIO: A practical guide

When considering scaling, the initial thought that may come to mind is scaling across multiple machines. However, it is important to ensure that you are fully utilizing the capabilities of a single machine before considering the use of multiple ones. With most of today's devices equipped with multicore CPUs, it opened the door for Applications to scale across these cores.
This blog aims to provide a comprehensive guide for scaling in Python, beginning with the options available on a single node and progressing to explore further possibilities
What do you need scaling for?
At first glance, it may appear to be a trivial question, but it is crucial to ask it. Understanding the use case that led you to consider scaling will provide valuable insight into which scaling technique is most appropriate. So, before we dive into the options available in Python, let's take a moment to explore this critical aspect.
Python, like many other programming languages, offers several options for scaling, including:
Multithreading (despite the presence of GIL, which we'll address)
Multiprocessing
Async/await and event loops (utilizing libraries such as asyncio)
Additionally, you can expand your options by incorporating external tools and technologies.
Threads
When you write a basic "Hello, World" program in Python, it runs on the main thread by default. This main thread serves as the entry point for most scripts and programs.
If you have a multi-core machine (which is likely), you can take advantage of threads to concurrently execute your functions by launching them in separate threads that operate almost simultaneously.

A funky diagram about how each process unit can handle multiple threads
Fundamentally, Each processing unit, or core, has the ability to handle multiple threads, but it cannot execute them simultaneously (in some processors there are 2 hardware threads per core which can allow executing 2 at a time per core). When a thread is running, it takes over the core until the operating system switches to another thread using a scheduler. The order of execution for threads is controlled by the operating system, meaning that you don't have direct control over the exact order in which the threads are executed. This can result in different behaviors on different operating systems.
+----------------------------+
| Operating System |
+----------------------------+
| Processor 1 Processor 2 |
| +-------------+ +--------+ |
| | Thread | | Thread | |
| +-------------+ +--------+ |
| | Thread | | Thread | |
| +-------------+ +--------+ |
| | Thread | | Thread | |
| +-------------+ +--------+ |
| | Thread | | Thread | |
| +-------------+ +--------+ |
| |
+----------------------------+
So after we grasped the core concept of Threads, let's write a simple function that can help us to use multiple threads for our functions.
from concurrent import futuresfrom typing import List, Callable_MAX_WORKERS_LIMIT_ = 50def multithread(function: Callable, args_list:List[List[object]], num_workers: int = None) ->Tuple[List[object], List[object]]: """Run a function in multiple threads Args: function (function): The function needed to be run in multithreads args_list (List[List[object]]):a list of lists for the function arguments num_workers (int, optional): number of thread workers . Defaults to None. Returns: results (List[object]), exceptions (List[object]): returning 2 lists, the first one for th final results of each thread, the second one is for the exceptions happened -if any- in any thread """ no_args = True if len(args_list)==0 else False exceptions, results = [], [] max_workers = _MAX_WORKERS_LIMIT_ if not num_workers else num_workers with futures.ThreadPoolExecutor(max_workers=max_workers) as executor: if no_args: num_workers = num_workers if num_workers else max_workers futs = [executor.submit(function) for _ in range(num_workers)] else: futs = [executor.submit(function, *args) for args in args_list] for fut in futs: if fut.exception(): exceptions.append(fut.exception) else: results.append(fut.result()) return results, exceptionsIn this example, we have a function called multithread this function takes 3 parameters
function: the function that we want to run in a multithreaded manner
args_list: List[List[object]]: the list that has the arguments that we want to pass to the function if needed
num_workers: the number of threads that we want to launch, if not specified by the number of the lists in the args_list
In this function, we use the futures module to construct a thread pool executor that will be responsible for launching our threads.
By submitting each thread, we tell the executor to launch them in the background and use the futs list to keep track of each thread and use it to check the results of it if it completes successfully or the exceptions if something happened during the execution. And then we return both lists of results and exceptions.
Let's have an example using this function
def add(x:int, y:int): return x + ymultithread(add, [[i, i+1] for i in range(100)])In this example, we are trying to launch a 100 thread running our simple add function which takes 2 integers and returns the sum. as we mentioned before, we put a limitation for how many threads we can launch in our thread pool executor. This is a safety mechanism to try to avoid situations when we run a large number of threads that cause any memory issues. It's always recommended to put a limit on it.
Let's take a step back and examine some of the main areas where multithreading is commonly employed:
Network applications: Multithreading is widely used in network applications, particularly when downloading or scraping data over the internet or a private network. Sequential processing can be excruciatingly slow in such scenarios.
Machine learning applications: In the machine learning pipeline, several steps can benefit from multithreading. For example, training multiple models in parallel is possible with packages like xgboost that use multithreading during training (often utilizing some C++ code under the hood).
Data processing pipelines: In most data processing pipelines, parallelization is crucial, and multithreading can be an effective solution, particularly for I/O operations.
GUI applications: While GUI may seem like a dated concept in the era of browser-based applications, it is still prevalent in many applications. Multithreading can help prevent your app from becoming unresponsive when launching resource-intensive tasks. By launching the tasks in a separate thread, the GUI can continue to operate normally without waiting for the task to finish.
But you may be wondering, how can we talk about multithreading in Python without addressing the elephant in the room - the GIL (Global Interpreter Lock)?
Multithreading & The GIL
The GIL is a locking mechanism that has one job, to make the CPython interpreter thread-safe by only allowing one thread to run at a time. The running thread is the one that holds the lock, when the lock is released, another thread gets the chance to run, and so on.
But how effective can multithreading be in the presence of the GIL? Well, it all depends on the nature of the task being performed by the thread. The GIL only imposes restrictions when running Python code. Therefore, if you use a library that utilizes C code, for instance, it would not be affected by the GIL. Additionally, when threads perform more networking and non-CPU intensive tasks, it would be okay since most networking packages are designed to release the GIL while waiting for a response.
However, suppose the thread is executing CPU-intensive tasks. In that case, the multithreaded code may be slower than its sequential version due to the overhead and context switch.
The main benifit of the GIL is to make your code thread-safe. Thread-safe means that your multithreaded code will not modify the same memory address at the same time. I know, other languages may have different ways to solve this, but this is how python approached this problem. This takes us to the second method to scale your python code, Multiprocessing.
Multiprocessing and escaping the GIL
With multiprocessing, you can launch multiple processes that represent independent instances of Python. Each process has its own memory space, and any global data or variables it had access to are copied. Additionally, each process has its own GIL.

Each process has its own memory that has exclusive access to it by default, with no sharing as we have in threads.
Multiprocessing shines the most in CPU-intensive tasks, that originally took too long to run. Spreading the load and parallelizing the CPU-intensive task on all the cores of your CPU leads to high utilization and faster execution. You need to take into consideration the cost of launching processes, as it would cost you more time if you used multiprocessing to parallelize a simple task that originally is fast on its own, and in these cases, you will notice that the sequential code will be faster than the multiprocessing version
Let's take a look and make a similar function as the multithread one but for multiprocessing using futures
from typing import List, Tupleimport multiprocessing as mpfrom concurrent import futuresfrom tqdm import tqdmfrom logger import LOGGERdef multiprocess(function: object, args: List[List[object]]) -> Tuple[List[object], List[object]]: # Num of workers will be set automtically to the max num of workers max_workers = mp.cpu_count() needed_workers = len(args) results = [] exceptions = [] if needed_workers <= 0 or needed_workers > max_workers: LOGGER.warning(f"Multiprocessing nodes num has been set to {max_workers}") workers = max_workers else: workers = needed_workers LOGGER.debug(f"Kicking off {needed_workers} workers to run {function.name}") with futures.ProcessPoolExecutor(max_workers=workers) as executor: jobs = [executor.submit(function, *i) for i in args] for job in tqdm( jobs, desc=f"Running {function.__name__} in parallel", ascii=True, disable=None, ): ex = job.exception() if not ex: results.append(job.result()) else: LOGGER.exception(f"{function.name} : {ex}") exceptions.append(ex) return results, exceptionsIn this example, we are creating a function that takes the task of running any function that you pass to it in multiple processes. You might have noticed that it's very similar to the multithread function. Actually, this is one of the reasons I like to use futures PoolExecutors. They provide a simple API that unifies the way you write code for both multithreading and multiprocessing. tqdm here provides a neat way to monitor the progress of the processes without printing in separate lines, it's not necessary at all but it feels nice to have.
Also, do you see the LOGGER importing line? let's talk about logging in the world of concurrency a little bit!
With multiple things running at the same time, logging seems tricky!
Logging is one of the most important things your prod system needs. Python has a very nice logging module that gives you a wide variety of configuration options, let's use it in making a very simple but helpful logger in situations like these
import loggingimport coloramacolorama.init(autoreset=True)LOGGER_NAME = "SuperSaiyanGodLogger" # or whatever super saiyan transformation you likeclass SuperSaiyanFormatter(logging.Formatter): format = "p[%(processName)s : %(process)d ] t[%(threadName)s : %(thread)d] | $ %(pathname)s (%(module)s) [%(levelname)s] : %(message)s" FORMATS = { logging.DEBUG: colorama.Fore.LIGHTBLACK_EX + format, logging.INFO: colorama.Fore.GREEN + format, logging.WARNING: colorama.Fore.YELLOW + format, logging.ERROR: colorama.Fore.RED + format, logging.CRITICAL: colorama.Back.RED + format } def format(self, record): log_fmt = self.FORMATS.get(record.levelno) formatter = logging.Formatter(log_fmt) return formatter.format(record)def init_logger() -> logging.Logger: logger = logging.getLogger(LOGGER_NAME) if not logger.hasHandlers(): handler = logging.StreamHandler() logger.setLevel(logging.DEBUG) handler.setFormatter(SuperSaiyanFormatter()) logger.addHandler(handler) return loggerLOGGER = init_logger()In this example, I want to focus on 2 main things
Having a custom formatter for your logger: You probably won't use any of the fancy colorings I'm adding here in the Logger, this is mostly for use on your machine. The main reason I'm adding it here is to give you a simple example of how easy you can build your own formatter with custom configs
Having a custom msg format structure: This one is important here. As you can notice here, I'm adding placeholders for information related to the process and the thread that this msg is coming from. This can give you some insights about what relates to what, which process, and which thread this msg is coming from. You can filter the msgs from a specific process or thread and use it in your debugging or tracing.
Multiprocessing using a Queue
As previously mentioned, processes have their own memory space that is not shared with other processes, unlike threads which have access to the same memory space. However, there is a technique that allows processes to share data with each other through the use of a queue. By implementing a shared queue, you can instruct your workers to listen and publish to specific queues, enabling communication between processes and creating a multi-stage multiprocessing pipeline. With multiple queues, workers in stage-1 can publish results in queue-1, which workers in stage-2 can use as input.
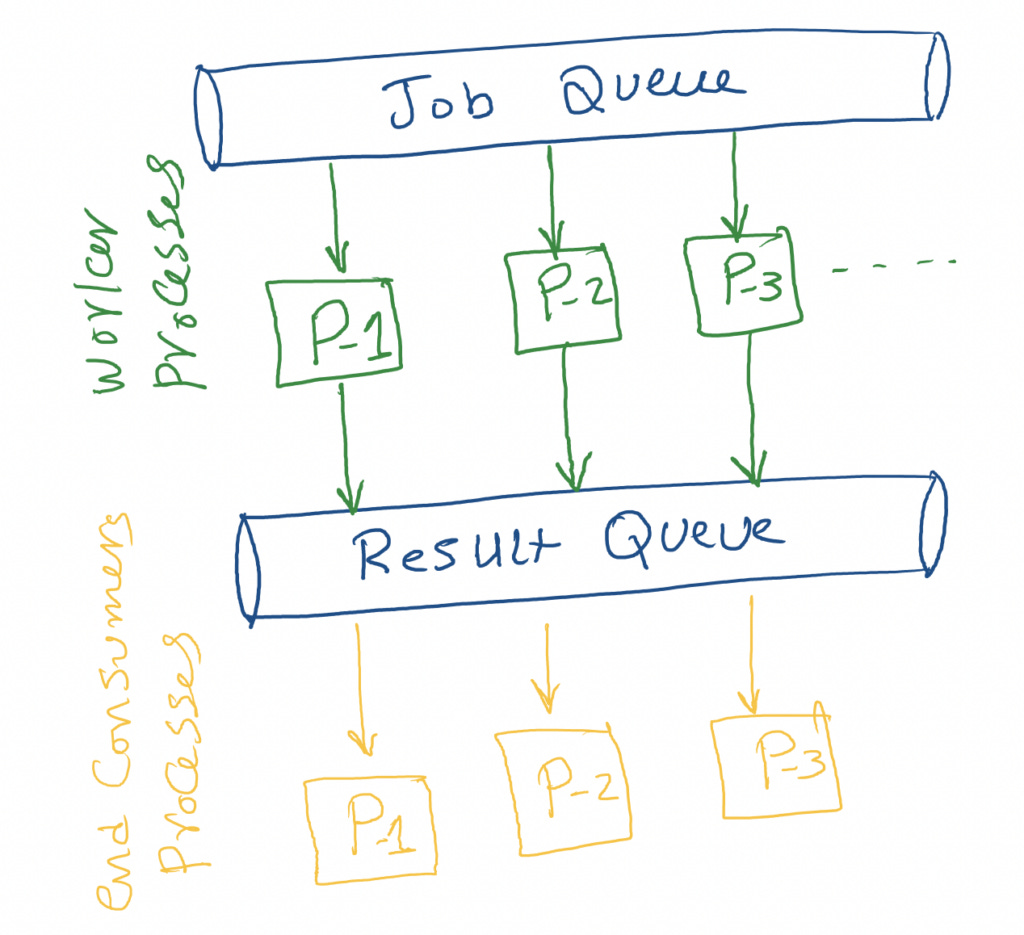
let's start with a simple example of queue-based multiprocessing.
from typing import NamedTuplefrom multiprocessing import Process, SimpleQueue, cpu_countfrom multiprocessing import queuesimport multiprocessing as mpfrom concurrent import futuresfrom typing import Listfrom logger import LOGGERfrom typing import Tupleclass Result(NamedTuple): num: int prime: bool# the diffentions here to be used in type hinting JobQueue = queues.SimpleQueue[int]ResultQueue = queues.SimpleQueue[Result]def is_prime(num: int) -> Result: if num > 1: for i in range(2, int(num/2)+1): if (num%i) == 0: return Result(num, False) return Result(num, True) return Result(num, False)def worker(job_queue:JobQueue, result_queue:ResultQueue) -> None: while n := job_queue.get(): LOGGER.info(F"Working on {n}") result_queue.put(is_prime(n)) result_queue.put(Result(0,False)) LOGGER.info("Done!!")def start_jobs(job_queue:JobQueue, result_queue: ResultQueue): processes = [] for _ in range(8): proc = Process(target=worker, args=(job_queue, result_queue)) proc.start() job_queue.put(0) # using it as a termination signal for the worker, just for the sake of the example but it's not the cleanest processes.append(proc) for proc in processes: proc.join()def consumer(result_queue: ResultQueue): while result := result_queue.get(): LOGGER.info(f" >> {result}") if result.num == 0: # terminating the consumer process using the termination signal we added breakdef start_consume(result_queue: ResultQueue): processes = [] for _ in range(8): proc = Process(target=consumer, args=(result_queue,)) proc.start() processes.append(proc) for proc in processes: proc.join()if __name__ == "__main__": job_queue: JobQueue = SimpleQueue() result_queue: ResultQueue = SimpleQueue() for i in range(999): job_queue.put(i) start_jobs(job_queue, result_queue) start_consume(result_queue) LOGGER.info("DONE!")In this example, I use 2 queues, the JobQueue and ResultQueue. The workers fetch the Jobs from the JobQueue and check if the number is a prime number or not, and in the end, it puts the result into the ResultQueue. After that we have consumers listen to the ResultQueue and get every object from it and just print it (for the sake of the simplicity in the example)
If you run this example using the Logger we wrote before, you will see the different processes running and can relate every result to a corresponding Process.
In most cases, when I face situations I need to use a queue-based architecture, I try to skip the hassle of managing processes using python multiprocessing and internal queues and use a queue management system that can scale up and down and manage spawning processes with more mature APIs. For example, using Celery (will talk about it shortly). Celery is written in Erlang, so it's independent of python limitations and goes beyond what you can do in python. No GIL headache or managing python processes and trying not to forget to join your processes to the main process. Besides all of that, using celery gives you the ability to scale beyond your machine and provide the capabilities to work in a distributed system manner if needed.
But before we talk about that, let's talk about another way to do concurrent tasks, Let's discuss AsyncIO
AsyncIO: "I'll call you back when I finish" Approach
AsyncIO is the official way for python to adopt the Asynchronous programming technique. It was first introduced by an open-source contributor and then was adopted officially by python starting from 3.4 and since then it was rapidly evolving and it was one of the most evolving and changing parts of python since then.
The main concept that AsyncIO is centered on is the event loop.
When using AsyncIO, an application can register special functions called "coroutines" to be called when certain events happen, like a file becoming available to read or a socket being ready to write. Coroutines work like generators and can give control back to the program while the event loop continues running.
In Python, a coroutine function is created using the async def statement. Similar to classic coroutines that use yield from, a native coroutine can delegate to another native coroutine using the await keyword. Even if the await keyword is not used in the body of an async def function, it will still be considered a native coroutine. However, the await keyword cannot be used outside of a native coroutine.
To make things simpler, Imagine yourself needing to do certain tasks on a Saturday, let's say you need to
Do your laundry
cook
calling Friends and Family
If you look at these tasks, besides cloning yourself into 3 and making each one of your clones take care of one of them. You can actually do them in an efficient way without the need for parallelizing. you can put your laundry in the washing machine, and leave it and start cooking, and while your food is in the oven, you can call your family. This is a simple way to describe the main concept of AsyncIO. it's started as a way to skip the waiting for tasks that you don't have control over and you can't make faster using your code, like network requests and IO operations.
import aiohttpimport asynciofrom logger import LOGGERasync def get(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: return responseasync def run(): results = await asyncio.gather(*[get("http://example.com") for _ in range(50)], return_exceptions=True) return resultsloop = asyncio.get_event_loop()results = loop.run_until_complete(run())LOGGER.info(f"Results: {results}")In this example, we are utilizing the asyncio module to execute multiple coroutines concurrently. The coroutines are attempting to make a GET request on the website http://example.com. Let's examine the code and understand how it works.
Initially, we are using aiohttp, which provides an implementation of the normal http module that is compatible with asyncio and is well-suited for asynchronous programming.
The get function is a simple function that makes a non-blocking HTTP GET request.
The run function creates 50 tasks that execute the get function and uses asyncio.gather to await on all of them simultaneously without blocking any of them. Once all of the tasks are finished, it gathers the results (including any exceptions) and returns them.
Next, we create our main event loop that will initiate the execution of all these coroutines and use it to execute the entry-point for our asynchronous program.
As previously mentioned, asyncio is a new feature in Python and undergoes frequent updates.
Escaping the language barrier (I mean the python language barrier)
So far we discussed concepts like Multithreading, Multiprocessing, and Asynchronous functions using python's built-in capabilities. And as a result, we sometimes are bounded by some limitations that relate to the language itself. Fortunately, Threads and processes are not originated in a certain language, it's an OS feature. So, we can use other tools to manage them far from the language limitation. Celery is one contestant for this, but there are others that can go even further
Celery is a broker-agnostic queue management system. Broker-agnostic means that celery can use different software as a broker, for example, Redis, RabbitMQ, and AmazonSQS. And if you are adventurous you can write your own broker and its own driver for Celery.
The great thing about celery is that it can run on a single machine or go beyond that and work in a distributed manner. for medium-sized queue-based projects (even some of the big ones) I'd choose Celery or at least I'd consider it.
I'm not going to go into details about Celery in this blog. You can learn more about it on the official website.
In conclusion, as the world moves towards Microservices and distributed systems, it is easy to get caught up in the idea that scaling across multiple machines is always necessary. However, it is essential to consider the potential benefits of optimizing your program on a single machine. While it may not be a viable option for large-scale systems, not all software solutions require that level of scalability. By keeping an open mind and exploring all possibilities, we can ensure that we are making the most efficient and effective use of our resources.
]]>